Imaginez que chaque service de votre entreprise parle une langue différente. Votre site e-commerce enregistre des ventes dans Shopify, votre CRM suit les prospects dans HubSpot, votre comptable manipule des exports bancaires en CSV et vos campagnes génèrent des rapports dans Google Ads. Résultat : vous passez des heures à compiler des tableaux Excel pour avoir une vague idée de votre performance globale. Ce casse-tête, c’est exactement le problème qu’un data warehouse vient résoudre.
Un data warehouse, ou entrepôt de données, est le point de ralliement unique de toutes vos données métier. Sa fonction principale est de centraliser des informations issues de sources variées — vos logiciels de vente, vos outils marketing, vos bases de production — dans un format harmonisé. Contrairement à une base de données opérationnelle conçue pour enregistrer des transactions en temps réel, le data warehouse est optimisé pour l’analyse et le reporting. On ne l’interroge pas pour savoir si la commande n°4589 a été expédiée il y a deux secondes, mais pour identifier les produits les plus rentables sur les douze derniers mois.
Qu’est-ce qu’un data warehouse d’entreprise ?
Un data warehouse, c’est l’entrepôt unique où toutes vos données métier sont consolidées, nettoyées et prêtes à être analysées pour prendre des décisions éclairées. Il transforme un chaos de chiffres éparpillés en une vision claire, fiable et actionnable de votre activité.
Concrètement, cet entrepôt fonctionne comme une bibliothèque d’entreprise parfaitement rangée. Au lieu d’avoir des livres (vos données) entassés en vrac dans des cartons (vos outils métiers), vous les cataloguez, les nettoyez et les rangez par thématique. Quand vient le moment de préparer votre rapport mensuel ou de valider une décision stratégique, vous n’avez plus besoin de fouiller partout : la bonne information est là, prête à l’emploi, croisée avec d’autres sources pour révéler des tendances invisibles autrement. C’est la fin des rapprochements manuels douloureux et des chiffres contradictoires entre le service marketing et la direction financière.
Pourquoi le data warehouse est devenu un incontournable pour votre business
Je vois encore trop de dirigeants de PME et ETI qui pilotent leur activité au feeling, en croisant les doigts pour que leur tableur Excel ne plante pas avant une présentation investisseur. C’est humain, mais c’est risqué. Le premier bénéfice d’un data warehouse, c’est de créer une source unique de vérité. Tout le monde dans l’entreprise regarde les mêmes chiffres, issus des mêmes données et calculés avec les mêmes règles. Fini les guerres de chapelles entre le chiffre d’affaires annoncé par l’équipe commerciale et celui pointé par la comptabilité.
Le deuxième gain est un gain de temps massif sur le reporting. Dans une PME classique, consolider manuellement les données de trois ou quatre outils peut prendre entre 15 et 20 heures par mois. Avec un data warehouse couplé à un outil de BI comme Looker Studio ou Power BI, cette charge tombe souvent à moins de 2 heures, le temps de rafraîchir les tableaux de bord. Une étude Forrester montre que le retour sur investissement médian des entrepôts cloud dépasse les 400 % sur trois ans, justement grâce à cette libération du temps de reporting.
La vision historique est un autre atout stratégique. Une base de production ne conserve souvent que l’état présent ou les dernières semaines. Un data warehouse, lui, garde la mémoire de vos données sur des années. Vous pouvez ainsi repérer les saisonnalités fines, comprendre les évolutions du panier moyen ou anticiper les périodes de tension de trésorerie. Et ces analyses ne reposent pas sur des données brutes : le processus d’intégration — l’ETL — nettoie, dédoublonne et uniformise tout au passage. Une PME que nous avons modélisée est passée de 20 heures à 2 heures de reporting mensuel. Cette disponibilité d’esprit retrouvée a permis à l’équipe dirigeante de se concentrer sur une stratégie de fidélisation qui a augmenté le chiffre d’affaires de 5 % en six mois.
Data Lake, Big Data, Data Mart : comment ne plus les confondre
Quand on commence à s’intéresser à la donnée, on tombe vite sur une jungle de termes qui semblent interchangeables. Data lake, Big Data, data mart… Le piège, c’est de les utiliser comme des synonymes et de se tromper d’outil au moment de trancher. Le data warehouse est votre couteau suisse pour la Business Intelligence sur des données structurées : chiffre d’affaires, noms de clients, dates de commande, indicateurs marketing. Tout y est rangé, schématisé, prêt à être visualisé dans un graphique.
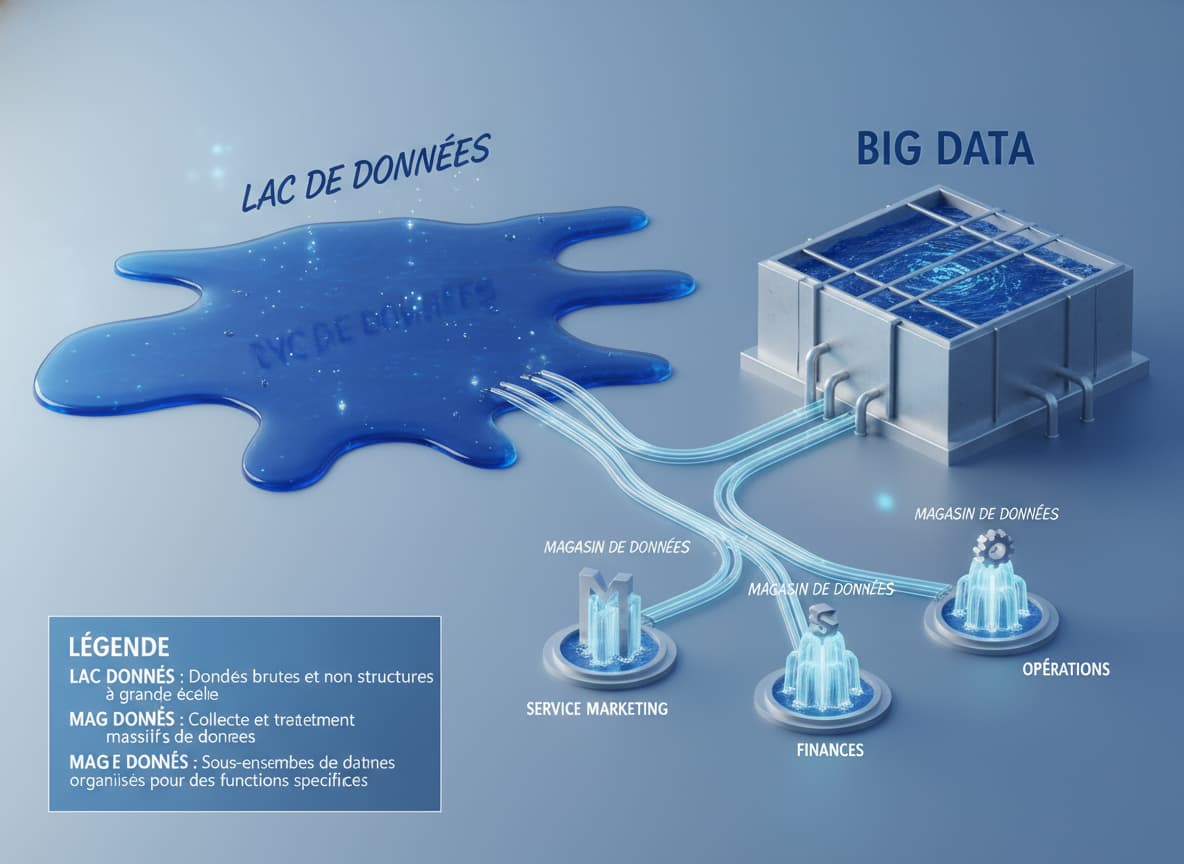
Le data lake, lui, est un immense réservoir où l’on déverse des données brutes de toutes natures : fichiers logs de votre site, flux de clics, images, données de capteurs IoT, conversations de chatbots. On ne sait pas toujours à l’avance ce qu’on va en faire ; c’est un terrain de jeu pour les data scientists et les projets de machine learning. La confusion entre les deux est tellement fréquente que la requête « Datawarehouse exemple » est l’une des plus tapées par les décideurs qui cherchent à visualiser la différence. Une banque, par exemple, utilisera un data lake pour stocker l’historique brut des connexions à son appli mobile, et un data warehouse pour générer ses reportings réglementaires trimestriels.
Data Warehouse vs Data Lake : les vrais cas d’usage
Le data warehouse est l’outil roi des KPI métiers : suivi du chiffre d’affaires, calcul de la marge, analyse de cohortes clients. Il exige que vous sachiez à l’avance quelles questions vous voulez poser. Le data lake, à l’inverse, accueille la donnée d’abord, et les questions viennent ensuite. C’est l’infrastructure idéale pour entraîner un algorithme de recommandation produit sur des millions de sessions de navigation non structurées.
Big Data et data warehouse : complémentaires, pas concurrents
Le Big Data désigne moins un outil qu’un défi : gérer des données en très grand volume, à haute vélocité et d’une grande variété. Votre data warehouse, surtout s’il est dans le cloud, peut intégrer des flux Big Data, mais uniquement après une phase de transformation et d’agrégation. Il ne stocke pas le détail de chaque micro-événement ; il en retient la substantifique moelle pour vos analystes. Les deux notions sont donc complémentaires : le data warehouse est une fenêtre d’analyse puissante sur un monde de données qui peut être immense.
Data Mart : le petit frère du data warehouse
Un data mart, c’est un sous-ensemble du data warehouse, taillé sur mesure pour un métier ou un service. Votre directeur marketing n’a pas besoin de voir les écritures comptables ; il veut juste ses performances de campagnes, son attribution et ses coûts d’acquisition. Le data mart marketing lui offre exactement ce périmètre, sans le bruit du reste de l’entreprise. C’est plus agile, moins coûteux à interroger, et cela responsabilise les équipes métier sans compromettre la gouvernance globale.
Les 4 types de data warehouse (et quand les choisir)
Il n’existe pas un data warehouse unique et passe-partout. Votre choix dépendra de la maturité de votre équipe, de votre politique de sécurité et de votre capacité à gérer de l’infrastructure. Voici les quatre grandes familles.
Le data warehouse d’entreprise (on-premise) est la forme historique. Vous l’hébergez sur vos propres serveurs, ce qui vous donne un contrôle absolu sur la sécurité. Le revers de la médaille, c’est un coût d’infrastructure élevé et une équipe technique dédiée. Les solutions comme Oracle Database ou IBM Db2 sont taillées pour des grands groupes aux exigences strictes. À l’opposé, le data warehouse cloud explose dans les PME. Des acteurs comme Snowflake, Google BigQuery ou Amazon Redshift vous louent une capacité de stockage et de calcul à la demande, sans serveur à gérer. C’est flexible, scalable, et l’investissement de départ est quasi nul.
Une variante intéressante est le data warehouse autonome, poussé par Oracle. L’idée : un système cloud qui s’auto-administre, se met à jour et se sécurise tout seul. L’avantage est évident pour une PME sans administrateur de base de données ; le risque est la dépendance à un unique fournisseur. Enfin, le data lakehouse, avec Databricks ou Delta Lake en fer de lance, brouille les frontières. Il applique la rigueur du data warehouse (transactions, schémas) directement sur le data lake. Le cas d’usage idéal : l’entreprise qui veut faire à la fois de la BI décisionnelle et du machine learning avancé sur les mêmes données, sans dupliquer les flux.
| Type | Description | Exemples de solutions | Avantages | Inconvénients | Cas d’usage idéal |
|---|---|---|---|---|---|
| On-premise | Entrepôt hébergé sur vos propres serveurs. | Oracle Database, IBM Db2, Microsoft SQL Server | Contrôle total, sécurité maîtrisée. | Coût matériel élevé, maintenance lourde. | Grande entreprise en secteur réglementé (banque, défense, santé). |
| Cloud | Entrepôt en mode SaaS, géré par le fournisseur. | Snowflake, Google BigQuery, Amazon Redshift | Paiement à l’usage, scalabilité élastique. | Dépendance au fournisseur, coûts variables. | PME en croissance, startup, besoin de flexibilité. |
| Autonome | Cloud qui s’auto-pilote via l’IA. | Oracle Autonomous Data Warehouse | Gestion simplifiée, haute disponibilité. | Coût supérieur, dépendance technologique. | PME experte métier sans compétences IT avancées. |
| Lakehouse | Fusion data lake et data warehouse. | Databricks (Delta Lake), Apache Iceberg | Polyvalence BI et ML, gouvernance unifiée. | Technologie récente, profils hybrides requis. | Entreprise data-driven avec besoins mixtes analyse et science des données. |
Comment fonctionne un data warehouse ? Architecture décodée
Je vous propose de décomposer le chemin que suivent vos données, de leur naissance dans vos outils à leur apparition sur un graphique. L’architecture d’un data warehouse moderne ressemble à une chaîne de traitement industrielle où la matière brute est raffinée étape par étape.
Les couches d’un data warehouse moderne
Imaginez un pipeline avec six grands blocs. D’abord, vos sources de données hétérogènes : CRM, site e-commerce, fichiers Excel, API marketing. Ensuite, une zone de staging, un sas temporaire où l’on dépose les données brutes sans les exposer. Le troisième bloc est le cœur du réacteur : le processus ETL/ELT (Extract, Transform, Load) qui extrait, nettoie, reformate et charge les données. Vient ensuite un entrepôt central dimensionné en modèle en étoile pour la performance. Au-dessus, les data marts taillent des vues par métier. Enfin, la couche de visualisation (Looker Studio, Tableau, Power BI) rend tout cela consultable.
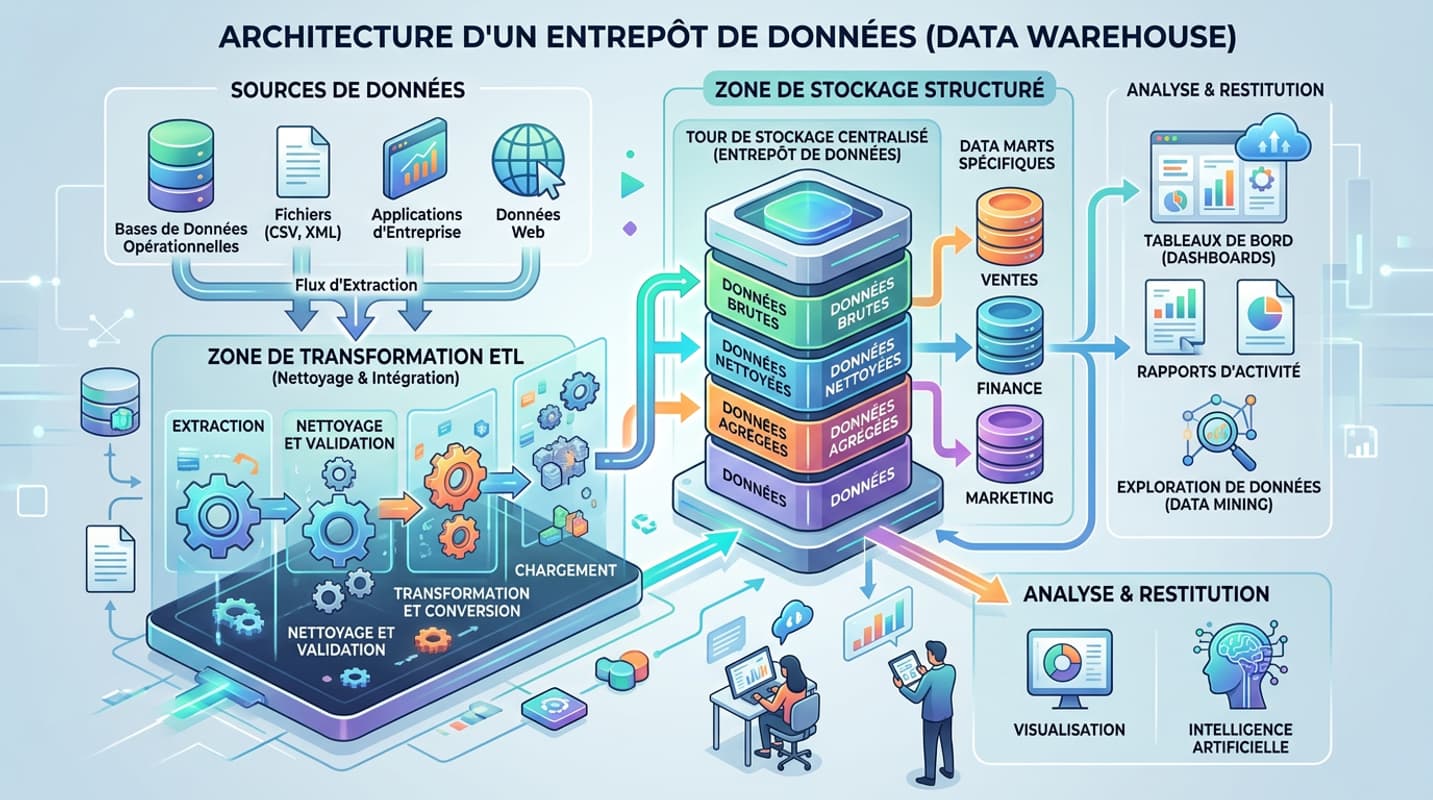
La grande force d’un système comme Snowflake ou BigQuery, c’est de séparer le stockage du calcul. Vous ne payez que lorsque vous lancez une requête. Et pour que ces requêtes soient fulgurantes, ces outils utilisent un stockage en colonnes : au lieu de lire une ligne entière, le moteur ne lit que les colonnes dont vous avez besoin. Pour un rapport mensuel qui agrége des millions de lignes, c’est un gain de performance décisif.
Comment une entreprise a gagné 30 % de productivité avec son data warehouse
Laissez-moi vous raconter l’histoire des « Délices Bio », une PME d’e-commerce alimentaire qui illustre ce qu’il se passe quand on passe de la débrouille Excel à une architecture digne de ce nom. C’est une fiction calquée sur des dizaines de cas réels.

Avant de se lancer, l’équipe perdait un temps fou. Chaque lundi, la responsable marketing exportait manuellement les ventes de Shopify, les leads de Salesforce et les sessions de Google Analytics. Elle passait deux heures à tout compiler dans un tableur, avec des risques d’erreur omniprésents. La direction prenait des décisions avec des chiffres qui dataient d’une semaine. Les Délices Bio ont adopté un data warehouse cloud (Snowflake) et un pipeline simple.
Étape 1 : Collecter les données sans douleur
La première décision a été d’arrêter les exports manuels. L’équipe a connecté Shopify, Salesforce et Google Analytics à leur entrepôt via des connecteurs natifs (Fivetran). Aucun développement lourd : quelques clics pour autoriser l’accès API, une sélection des tables à synchroniser, et le flux était lancé. En moins d’une journée, la collecte était automatisée.
Étape 2 : Nettoyer et harmoniser avec l’ETL
Le vrai chantier, c’était la qualité. Les noms de colonnes différaient (« date_commande », « CreatedDate »), les formats de devise se mélangeaient, des clients apparaissaient en double. La couche de transformation (avec dbt) a défini des règles une fois pour toutes : normalisation des champs, dédoublonnage par email, conversion en euros. Chaque nouvelle ligne est instantanément nettoyée, et les erreurs de reporting liées aux doublons ont chuté drastiquement.
Étape 3 : Stocker pour l’analyse
Les données propres ont été modélisées dans un schéma en étoile simple : une table de faits « Commandes » au centre, reliée aux tables de dimensions « Clients », « Produits » et « Temps ». Cette structuration permet de répondre en une requête à « quel est le panier moyen de nos clientes de plus de 35 ans sur les six derniers mois ? ». Avant, cette question demandait trois tableaux croisés et une demi-heure de manipulations.
Étape 4 : Visualiser et décider plus vite
La dernière brique a été Looker Studio, connecté à l’entrepôt transformé. Un tableau de bord principal affiche le chiffre d’affaires, les produits phares, le coût d’acquisition client et le taux de réachat, rafraîchi en direct. Un matin, la responsable marketing a repéré une hausse soudaine du panier moyen sur une catégorie de produits bio pour bébé. L’équipe a lancé une campagne ciblée dans l’après-midi, au lieu d’attendre le rapport de fin de mois.
Le bilan est éloquent : l’automatisation a libéré 10 heures par semaine de travail de consolidation. Les erreurs dans les reportings ont été réduites de 80 %. La capacité à réagir en temps réel s’est traduite par une hausse de 12 % du panier moyen. La productivité, mesurée par le rapport entre le temps investi et la valeur des décisions prises, a bondi de près de 30 %. Sans l’investissement de trois semaines de consulting et 400 euros mensuels dans leur stack de données, ces gains n’auraient jamais émergé de leurs tableurs silotés.
Checklist : 7 questions pour ne pas vous tromper dans le choix de votre data warehouse
Avant de contacter un commercial ou de vous lancer dans un proof of concept, posez noir sur blanc les réponses à ces sept questions. Elles vous éviteront de choisir une solution inadaptée qui dort dans un coin six mois plus tard.
- Quels types de données et volumes prévoyez-vous ? Identifiez si vous manipulez surtout des données structurées (transactions, clients) ou des flux semi-structurés (logs, JSON). Estimez le volume à 1 ou 3 ans pour calibrer la puissance de calcul.
- Quel budget et quel modèle de licence (SaaS ou on-premise) ? Le cloud est un coût opérationnel variable ; l’on-premise un investissement fixe lourd. Vérifiez la tarification : à la donnée stockée (BigQuery) ou au crédit de calcul (Snowflake).
- Quelles compétences techniques avez-vous en interne ? Si personne ne maîtrise le SQL ou l’administration système, fuyez les solutions on-premise ou complexes. Tournez-vous vers un data warehouse autonome ou un cloud prêt à l’emploi.
- Quelle intégration avec votre cloud existant (AWS, GCP, Azure) ? Si toute votre infrastructure est déjà chez un fournisseur, utiliser son data warehouse (Redshift, BigQuery, Synapse) réduit la complexité réseau et optimise les coûts de transfert.
- Quelles exigences de performance attendez-vous ? Un rapport de clôture comptable lancé la nuit n’a pas les mêmes contraintes qu’un tableau de bord client en temps réel. Le SLA et le temps de réponse doivent correspondre à vos besoins réels.
- Quels besoins en gouvernance et sécurité (RGPD) ? Si vous gérez des données personnelles européennes, la localisation est critique. Votre outil doit permettre l’anonymisation, le suivi des accès et la purge automatique.
- La solution est-elle évolutive et compatible lakehouse ? Même si vous n’en avez pas besoin aujourd’hui, vérifiez si la plateforme supporte des formats ouverts (Iceberg, Delta Lake). C’est votre assurance contre l’enfermement propriétaire.
FAQ : vos questions pratiques sur le data warehouse d’entreprise

C’est quoi un data warehouse ?
Un data warehouse est un système centralisé qui stocke des données structurées provenant de sources multiples pour faciliter l’analyse et la prise de décision en entreprise. Il permet de croiser des indicateurs et de produire des rapports fiables, unifiés et historisés.
Différence entre Big Data et data warehouse ?
Le Big Data désigne un défi de volume, de variété et de vélocité des données. Le data warehouse est un outil structuré pour l’analyse décisionnelle. Il peut intégrer des flux Big Data, mais seulement après leur transformation et leur agrégation.
Qu’est-ce qu’un logiciel datawarehouse ?
Un logiciel de data warehouse est la plateforme qui implémente l’entrepôt de données, comme Snowflake ou Amazon Redshift. Il inclut des capacités de stockage, de requêtage à haute performance, et souvent des fonctions avancées de gestion de l’ETL ou de sécurité.
Quelle est la différence entre un data warehouse et un data lake ?
Le data warehouse stocke des données structurées et schématisées, prêtes pour la BI. Le data lake conserve des données brutes, souvent non structurées, pour la science des données. Le premier impose un schéma à l’écriture, le second à la lecture.
Comment choisir un data warehouse pour son entreprise ?
Évaluez vos volumes de données, votre budget prévisionnel, vos compétences techniques internes et votre cloud existant. Privilégiez une solution évolutive, sécurisée et compatible avec vos besoins RGPD, idéalement dans un modèle SaaS pour une PME en croissance.
Quels sont les types de data warehouse ?
On distingue le data warehouse d’entreprise (on-premise), le cloud, l’autonome et le data lakehouse. Chaque type répond à des besoins spécifiques en termes de contrôle de l’infrastructure, de scalabilité et de simplicité de gestion quotidienne.
Quels sont les avantages concrets d’un data warehouse ?
Il unifie toutes vos données métier, fiabilise et accélère les reportings, et améliore radicalement la prise de décision. Les PME constatent une réduction drastique des erreurs manuelles et un gain de temps de reporting de l’ordre de 80 %.
Faut-il un data warehouse ou un data lake ?
Pour des analyses décisionnelles sur des données structurées, un data warehouse est suffisant et plus simple à appréhender. Si vous collectez massivement des données brutes et souhaitez faire du machine learning, un data lake ou une architecture lakehouse sera plus adapté.
Quel est le rôle de l’ETL dans un data warehouse ?
L’ETL (Extract, Transform, Load) extrait les données de vos sources, les nettoie en éliminant les doublons et les erreurs, les transforme dans un format unique, puis les charge dans l’entrepôt. C’est l’étape critique qui garantit la qualité et la cohérence des analyses.